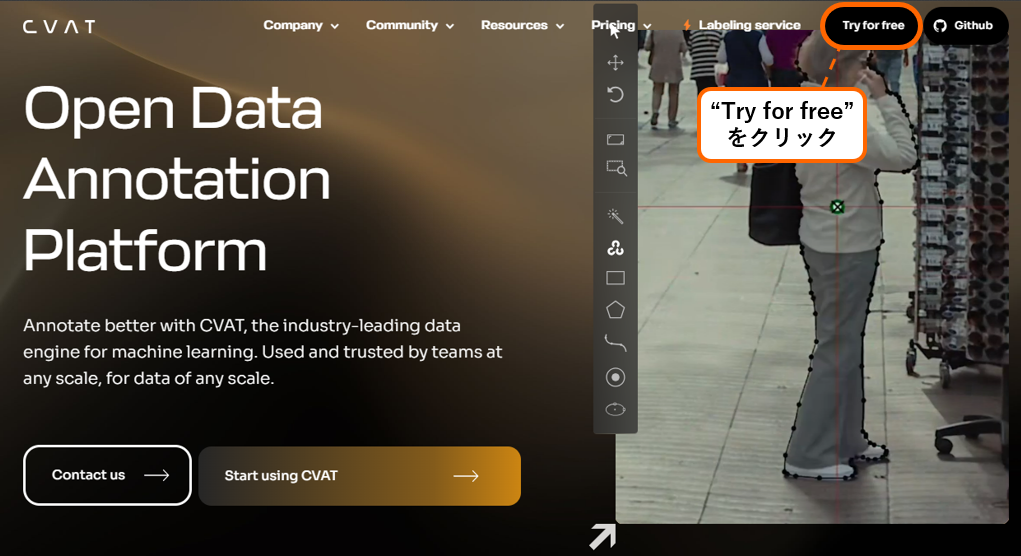
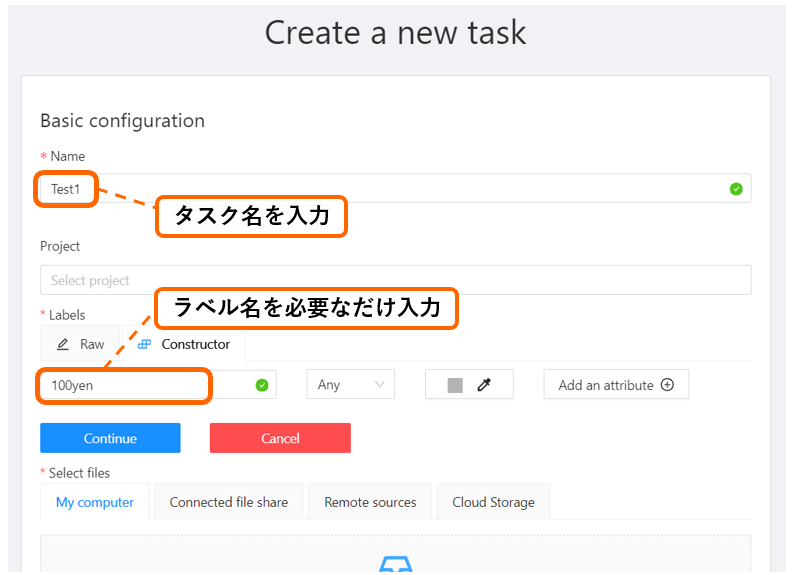
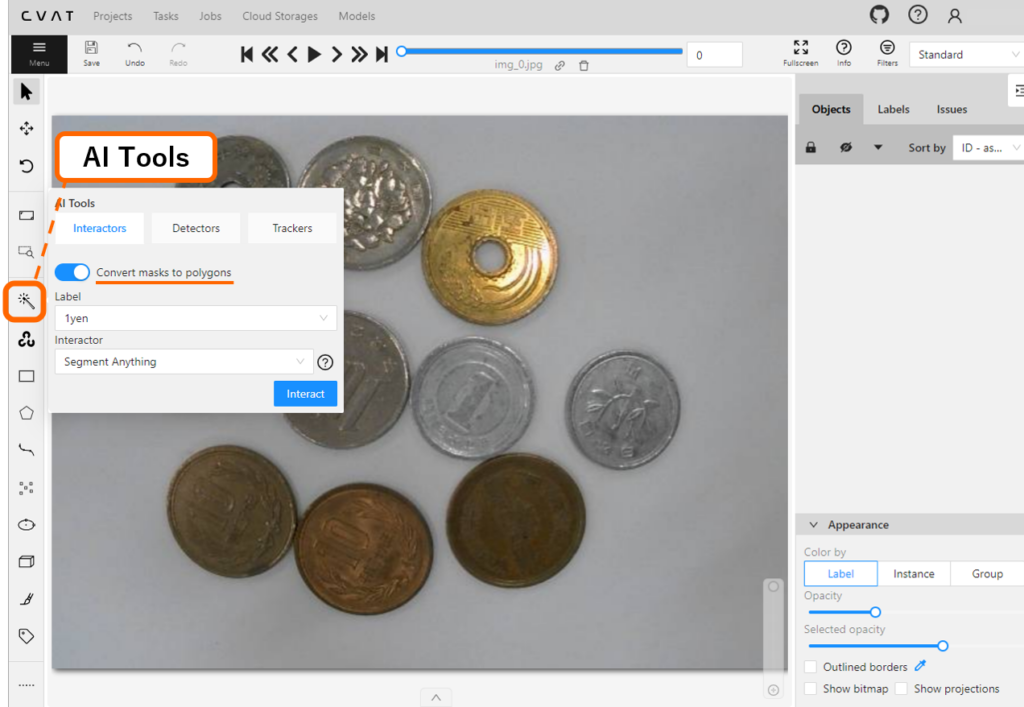
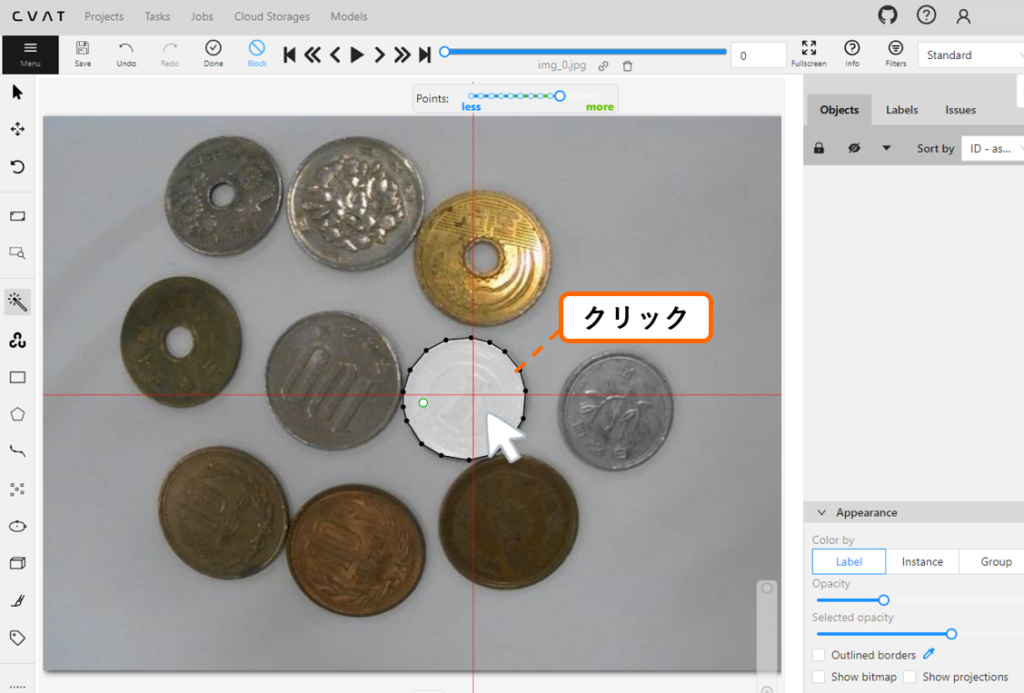
Scratch(スクラッチ)
ここでは Scratch を使ってスーパーマリオブラザーズのような2次元のアクションゲーム を作ってみたいと思います。
主人公の作成
まずは、マリオで言うところのマリオ、真ん中で動く主人公を作ってみます。
Scratch では、画面上に表示する一つ一つの要素を「スプライト」 と呼びます。主人公もスプライトで作成します。スプライトに使用する素材は、Scratchにデフォルトでいくつか用意されていますが、これだけでは物足りないので、フリー素材などを探して活用する
ここでは、Superpowers Asset Pack
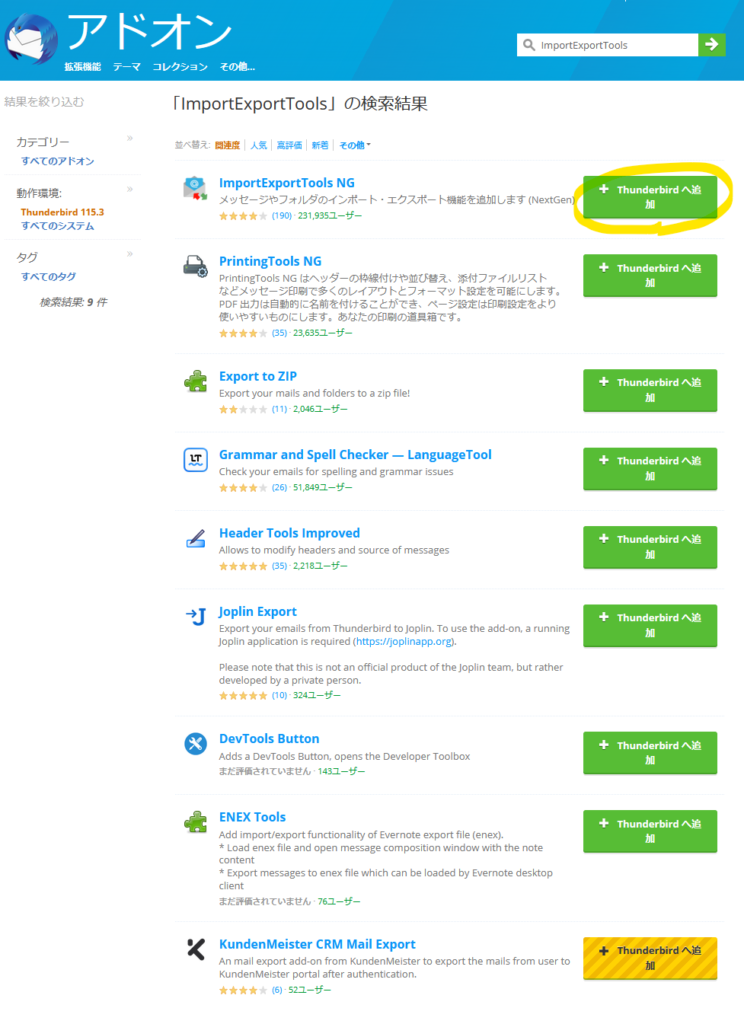
① こちらの Superpowersのサイト にアクセスして、「Download Now」ボタンをクリックします。
② 「No thanks, just take me to the downloads」をクリックします。
③ 「Superpowers Mega Asset Pack (1200+ files!)」の横の「Download」ボタンを押します
④ ZIPファイルがダウンロードされるので解凍して利用します。
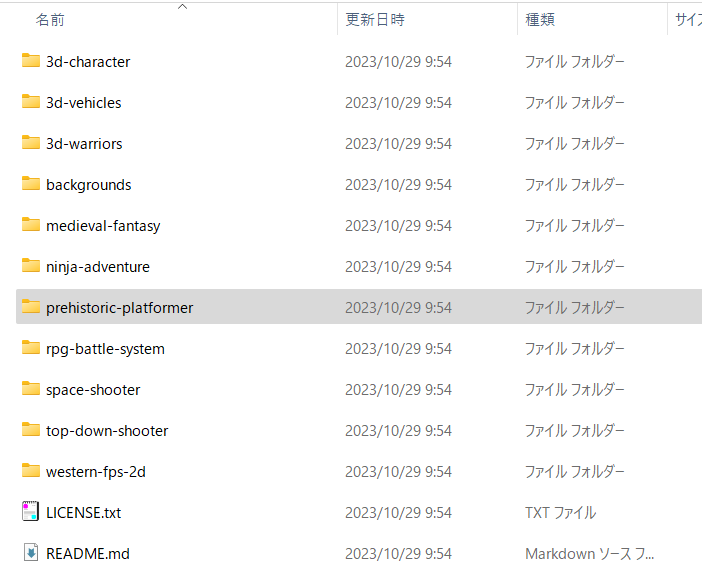
解凍すると下記のようなフォルダ構造になっています。中身にどのような素材が入っているか覗いて確認してみてください。
ここではアクションゲーム用の素材がまとめて入っている「prehistoric-platformer」を使ってみたいと思います。
主人公になる素材は「characters/playable」フォルダ内に入っています。
中身を見ると下記のような画像が入っています。
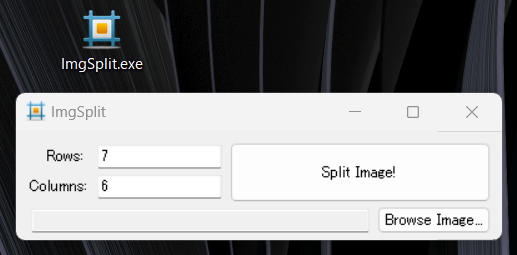
Scratchで使用するにはこれを一つ一つに分割した画像にしたいので、フリーソフトの分割ツールを使って分割したいと思います。ここでは「ImgSplit 」という分割ツールを使います。
こちらのツールを使って分割を実行すると、下記のように別々の画像ファイルとして作成することができます。
素材が準備できたので実際にScratchでプログラミングしていきたいと思います。
素材を使ってスプライトを作る
Scratchには ①オンライン版と②オフライン版があります。
①オンライン版は、Scratchのサイトにアクセスし、ブラウザ上からプロジェクトの管理やプログラミングする方法です。ブラウザから利用できるので、パソコンに専用ソフをインストールさせておく必要がなく簡単に始められますが、インターネットが接続出来る環境でなくては、使用することが出来ません。
②オフライン版は、事前にインターネット経由でソフトをインストールしておき、PCのローカル環境でロジェクトの管理やプログラミングする方法です。インターネットが繋がらない環境でも学習を進めることが出来ますので場所を選びませんが、インターネット経由でソフトをダウンロードしインストールをして学習環境を設定しておく必要があります。
ここでは手軽に始められるオンライン版にて説明します。
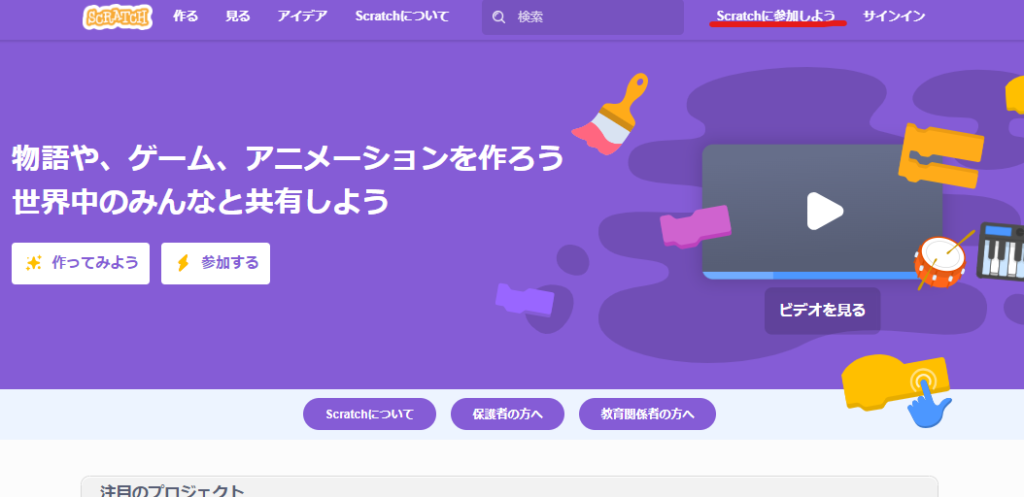
Scratch のサイトに行き、右上の「Scratchに参加しよう」から、アカウントを作ります。
アカウントを作ったら、画面左上にある「作る」をクリックするとプロジェクトを作成することができます。
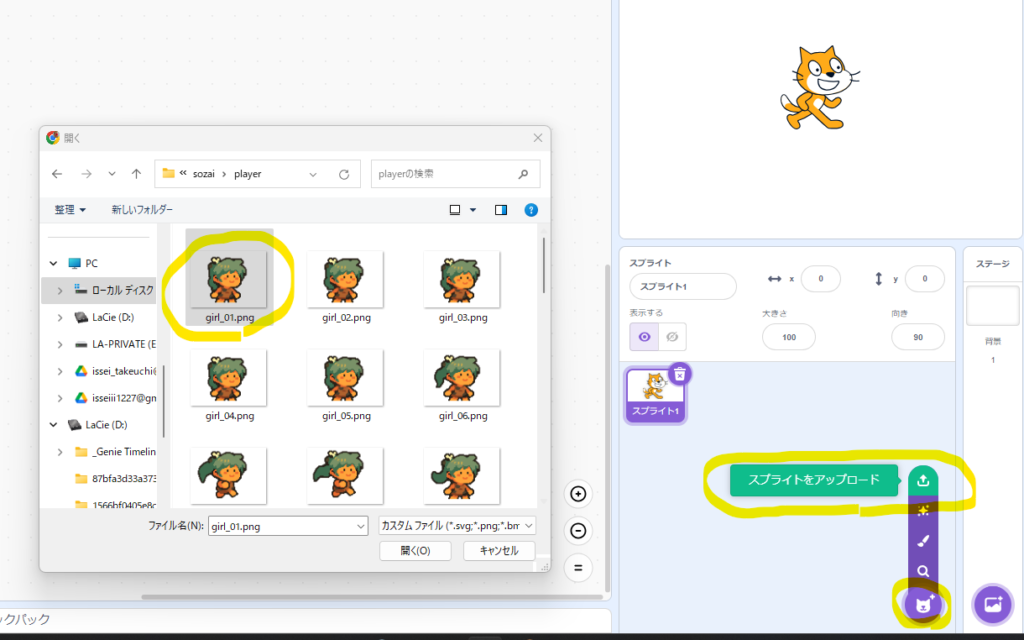
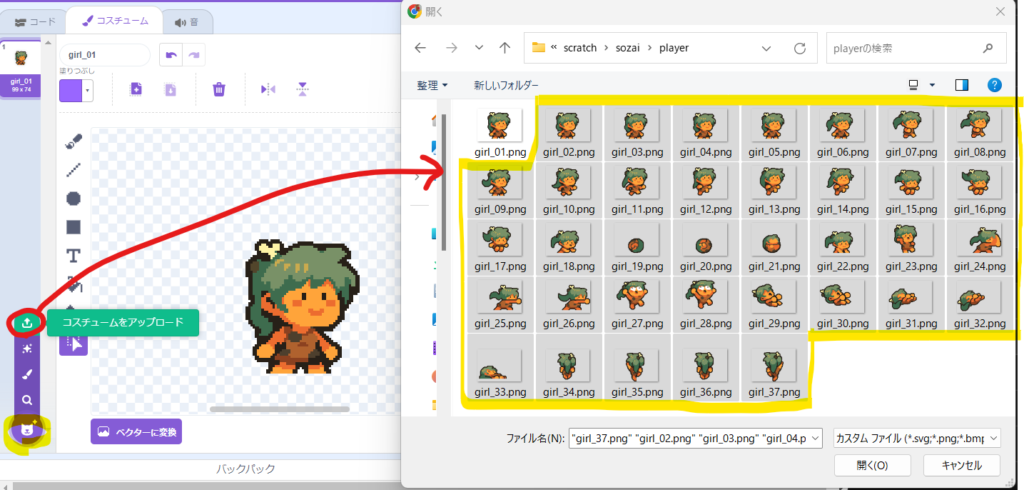
では早速スプライトを作ってみたいと思います。右下の「猫の顔+」のアイコンから「↑」スプライトをアップロードをクリックし、先ほど分割したキャラクターの画像を一つ選択します。
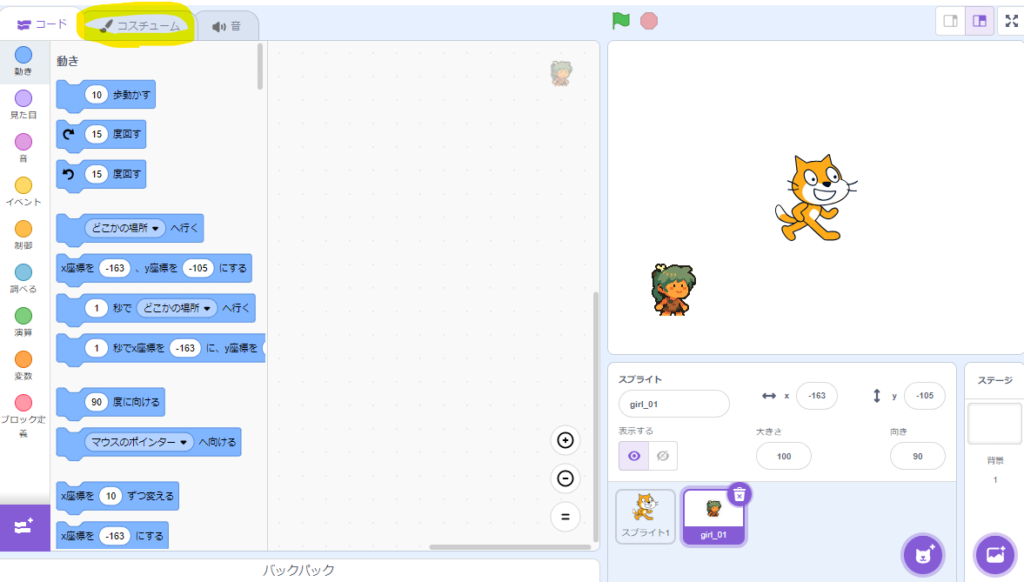
そうすると画面にキャラクターが現れます。右下のスプライト選択ウインドウから、アップロードしたキャラクターを選択し、左上のコスチュームタブを選択します。
「コスチュームをアップロード」をクリックし、先ほど分割した残りの画像を選択して、「開く」をクリックします。
これでスプライトの素材のアップロードは完了です。
スプライトを動かす
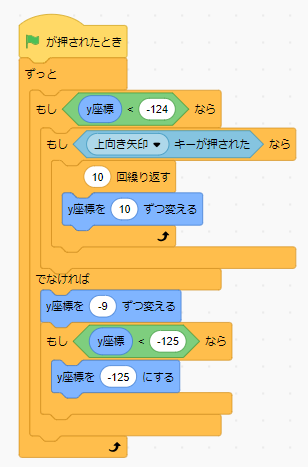
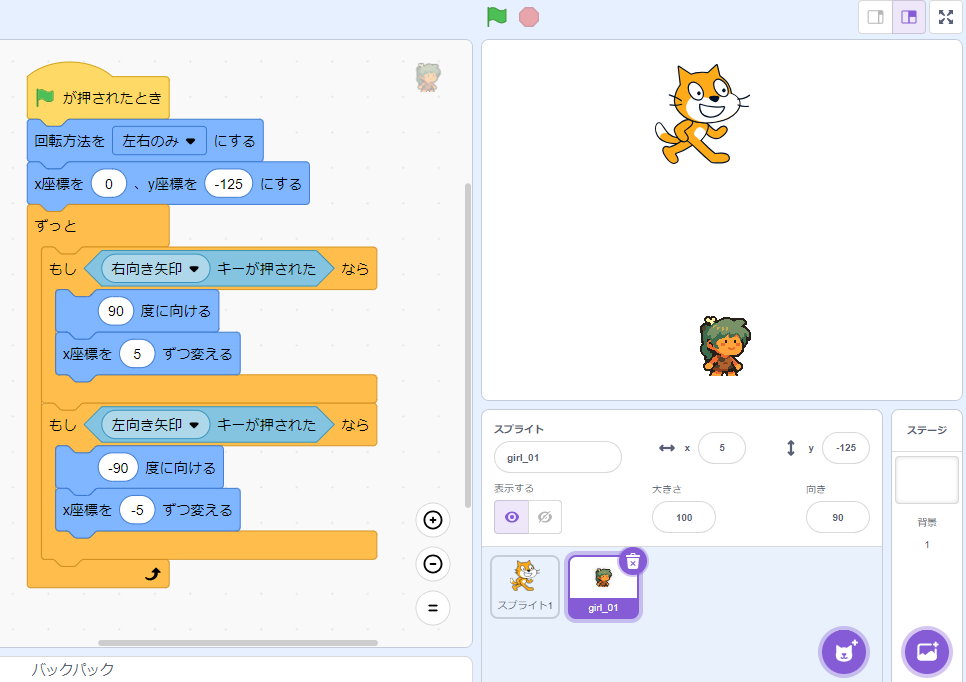
次にスプライトを動かすコードを生成します。下記のようにコードを入れてみましょう。
キャラクターが左右に滑るように動くようになったと思います。
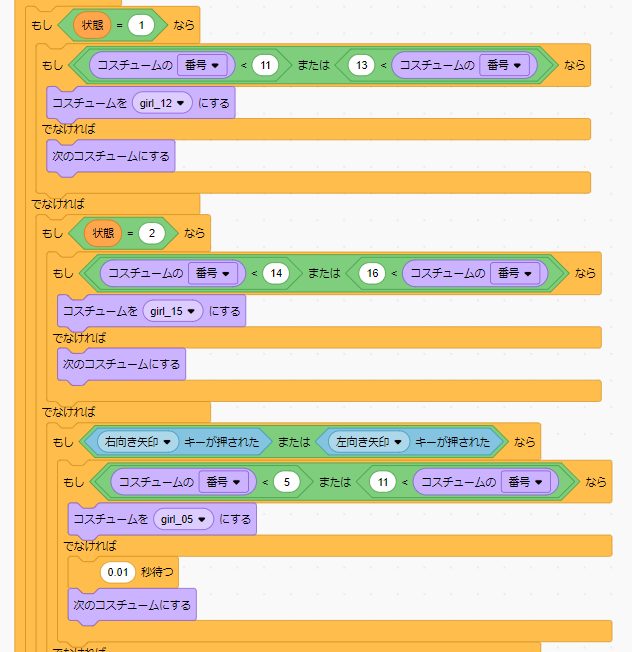
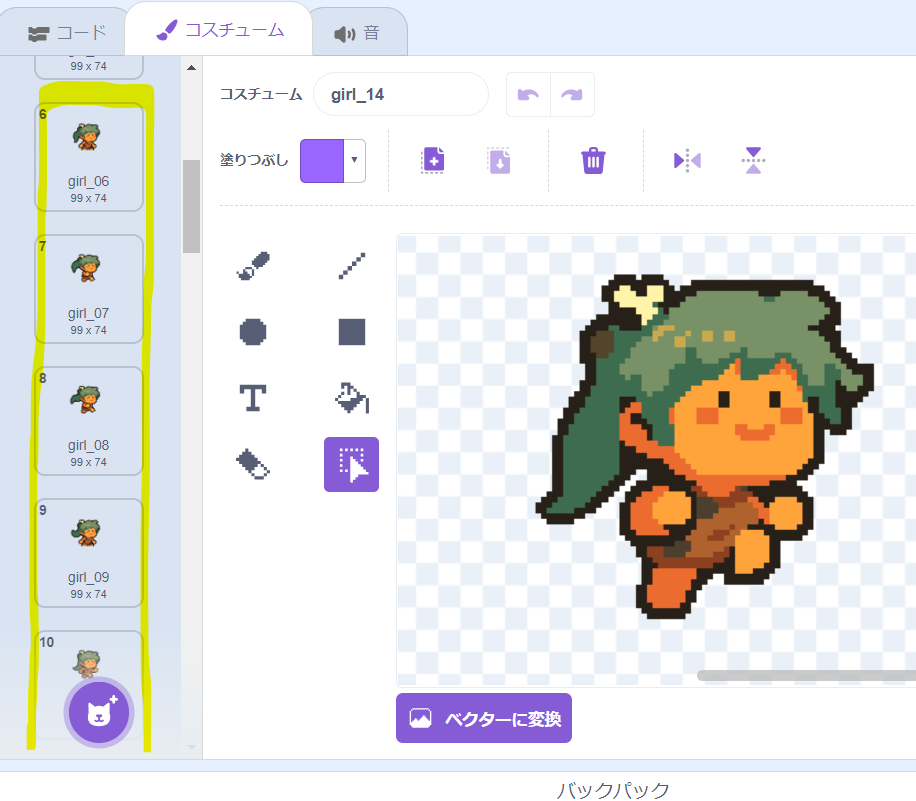
次にもっと動いている感じを出すために、走る動作を加えてみます。スプライトのコスチュームを確認すると、6番~11番と順番に変化させる と、走る動作になっていることが分かります。
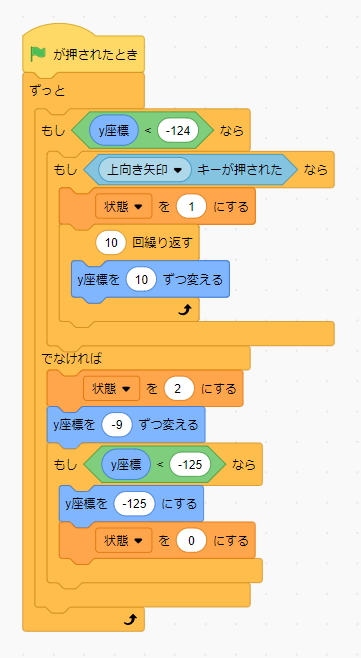
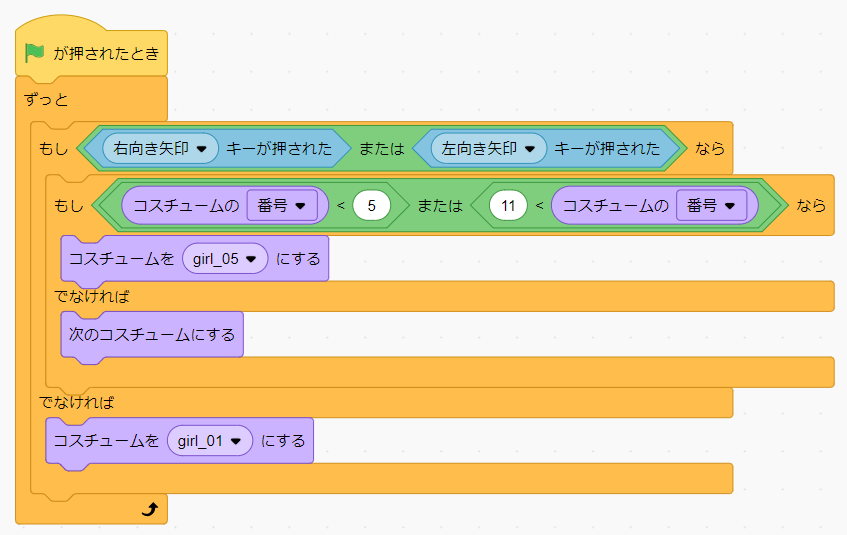
つまり、右か左のキーが押され続けている間、コスチュームを6 ⇒ 11 に変化させるコードを実装すればOKです。下記のコードを先ほどのコードに加えて、別のブロックとして記述します。
スプライトが走る動作をしながら左右に動くようになったと思います。